The execution model of AWS Lambda@edge with Cloudfront's two- and three-tiered architectureJuly 2, 2021
The introduction of Lambda@Edge in 2016/2017 was probably the most significant update to AWS Cloudfront in the last decade. By enabling customers to run code directly in Cloudfront’s Points-Of-Presence (POPs), AWS was at the forefront of edge computing, leveraging countless use-cases, from simple header manipulation, to custom authentication workflows.
Lambda@Edge relies on a simple execution model that defines four different types of lambda functions that can manipulate CloudFront request or response objects:
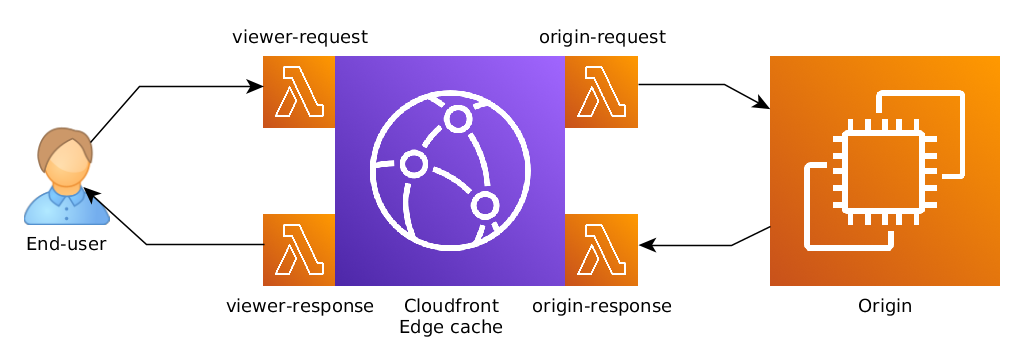
The four different lambda types are:
| Lambda type | Location | Executes | Manipulates |
|---|---|---|---|
| viewer-request | Before cache | Every request | Request |
| origin-request | After cache | On cache misses | Request |
| origin-response | After cache | On cache misses | Response |
| viewer-response | Before cache | Every request | Response |
A few immediate observations:
- Cache hits do not trigger Origin-request and origin-response lambdas. Therefore, those lambdas do not impact the performance of cache-hits.
- Viewer-request and viewer-response lambdas are triggered on every request. This can get quite expensive on Cloudfront distribution with significant traffic.
A two-tiered caching architecture
This execution model assumes a single Cloudfront cache between the end-user and the origin. According to this model, if the POP (edge cache) hit by the end-user is Marseille, France (MRS50), all four lambdas would be run there, and that POP would send all cache misses to the origin.
In reality however, Cloudfront does not forward cache misses from the edge cache to the origin, but will send the request to a regional edge cache first. This is a secondary layer of cache, in the same geographic area as the edge cache, that has much more storage, and is more likely to have the file cached: it’s a “Super-POP” of sorts! Cloudfront provides a map with the regional POP locations.
This is how this two-tier caching system would work without lambdas:

So, where are lambdas executed, after all? Lambdas@Edge are always executed in the regional edge cache. Edge caches can not run lambdas@edge functions - only Cloudfront functions which we will discuss later.
This gives us the following:
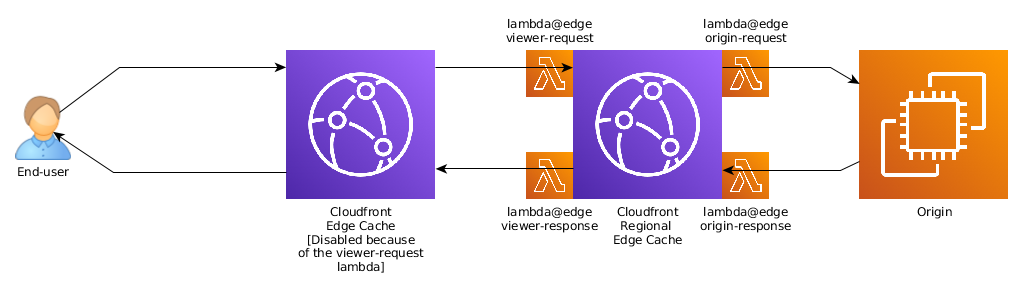
One of the non-obvious implications is that, because lambda@edge functions can only run in a regional edge cache, and because “viewer requests” lambdas need to run on every request and before the cache, attaching a viewer-request lambda to a distribution disables caching in the edge cache.
Edge caches might still be used to terminate the TCP connection closer to the user, but won’t be able to cache files anymore, increasing cache-hits latency.
Origin shield, or Cloudfront’s new three-tiered caching architecture
At the end of 2020, Cloudfront announced Cloudfront Origin Shield, an additional caching layer, close to the origin, to help further reduce the number of requests sent to the origin.
If there were previously 10 regional caches, for a new file, it would take at least 10 requests to the origin to have that file cached in all edge regional caches. With an origin shield, since all regional caches would send the request through that shield, only a single request to the origin would be executed.
Of course this complicates the Lambda execution model.
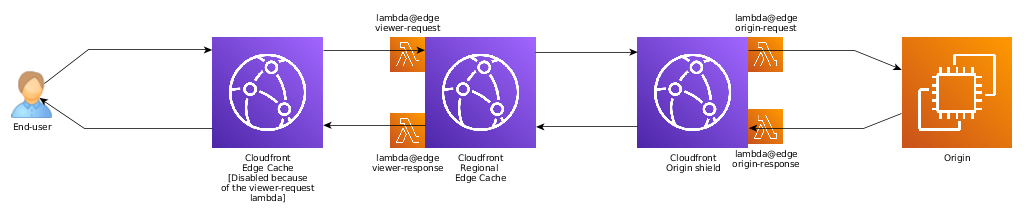
Indeed, origin-requests need to run after the cache. Adding an origin shield to your Cloudfront distribution changes where your origin-* lambda are executed: they will now be run at the origin-shield instead of the regional cache. Depending on your use-case, this might be appropriate - but it is important to note that origin-requests are now executed close to the origin, and potentially quite far from the user and the edge.
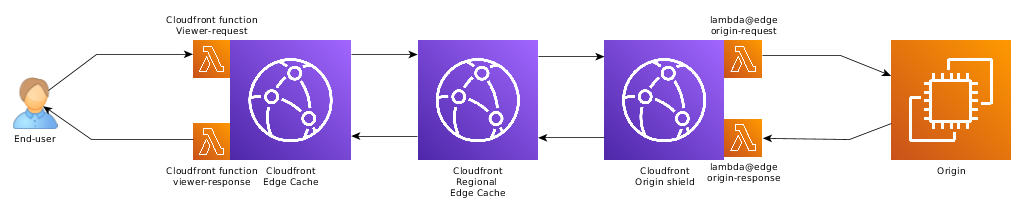
Cloudfront functions
Because of the limitations of lambda@edge, AWS introduced Cloudfront functions. Cloudfront functions are lightweight lambda@edge functions that are small enough to run in edge caches, allowing improved latency: they run closer to the user, and have a smaller cold-start time. They however come with more constraining restrictions, especially a maximum of 1ms of execution time.
Cloudfront functions can be used for viewer-request and viewer-response functions, in lieu of lambda@edge viewer-* functions, and can be combined with lambda@edge origin-request and origin-response functions.
However, because viewer-request Cloudfront functions execute at the edge cache, and lambda@edge in the regional edge cache, it is not possible to combine a viewer-* Cloudfront functions with a viewer-* lambda@edge functions.
This gives us this final execution model, replacing the viewer-* lambda@edge functions by Cloudfront functions:
Closing Thoughts
As Cloudfront evolves from a simple architecture to a two- to three-tiered architecture, the lambda@edge execution model remains unchanged and hides this increased complexity. In many cases this abstraction makes it easier to reason about Cloudfront, although in some cases it might also lead users to build code on incorrect assumptions.
Hopefully this article helps clarify the situation!
The curious case of the CDN Cache-HISS > < Solving the CDN post-purge thundering herd problem: The PurgeGroup pattern