The curious case of the CDN Cache-HISSAugust 6, 2023
A few years ago, I was asked to take a more active role maintaining the CDN configuration of the company I work for. My knowledge of CDNs at the time was pretty basic and could be summarised by the following diagram:
“Sure, I got this”. And for a short time, things were good. But soon after, I was asked the following question:
“We are reviewing the performance of a client’s requests - several of their requests are quite slow, despite being Cache HITs. What’s going on?”.
And I soon realised, who would have guessed - things are never that simple. Cache HITs? Cache MISSes? Cache-HIT ratios? Things have gotten complicated, and those terms don’t make all that much sense anymore..
Let me introduce you: the cache HISS: a little bit cache HIT, a little bit cache MISS… and it comes in different flavours!
Definitions
Before going further, let’s define some important terms. Believing there was no standard definition, I was going to define these myself, until it was pointed out to me that a RFC from 2022 did just that. We will therefore use the following definitions:
- A cache HIT is a request where the response is served by the cache. The request was not forwarded to the origin.
- A cache MISS is a request that was forwarded to the origin.
- The origin is the infrastructure the CDN forwards requests to.
HTTP 304 - Not Modified
Imagine you are managing a CDN in front of a file repository (the origin). All the files in the repository are quite large, maybe several GBs. Those files do change, but really quite rarely. It is acceptable if new versions of a file are served within one hour of being uploaded, therefore you configure a Time-To-Live (TTL) in your CDN: the CDN should cache the file for not more than one hour after retrieval.
Assuming each file is requested several times per hour, this would mean that the CDN would need to download each file again every hour, to ensure it has the latest version in cache. In practice, a CDN has multiple caches around the globe (Points-of-Presence or POPs), so it might be worse: each POP might need to refresh every file every hour.
This could quickly become very expensive and impractical: your origin would be constantly sending many large files that have not changed to the CDN.
To not overload the origin, modern CDNs supportsETags. The Etag is an optional response header returned by the origin, its value corresponding to a specific version of the file being served. How this ETag is calculated has never been specified and can vary by implementation.
If the CDN receives a request for which the cached file’s TTL has expired, and the file was previously returned with an ETag response header, it would add a if-none-match request containing the value of that Etag. This is akin to telling the origin “Can you send me file X? I already have this version in cache, so if it has not changed, do not sent me the whole file again”.
If your origin supports ETags, it will compute the ETag of the file requested. If the file has not changed, the computed ETag will match the ETag sent by the CDN in the if-none-match header, and instead of sending the whole file back, your origin will return a HTTP/304 Not Modified response. The CDN would then renew the TTL of the file in cache using the information returned by the origin in the cdn-cache-control and cache-control headers, and serve the file it has in cache.
What happened?
- The request was served by the CDN, using content that was previously cached
- However, the request went to the origin, and potentially required some computation there.
According to our definition - this is a cache MISS. Somewhat unintuitively though, the request was actually served using data from the CDN cache.
Is this a Cache-HISS?
Request coalescing/collapsing
To improve on the previous architecture, you decide that setting a TTL of 1h on your files is not that great after all. You need to wait up to an hour for the new versions of your files to be served, and the revalidation requests from the CDN are not very efficient, since most of your files never change!
You decide that having a much higher TTL (1 year), and purging files from the CDN when they change would mean fewer revalidation requests to your origin, and ensuring the new versions of the files are available much sooner.
Now - some of the files are requested quite a lot. Especially after a file changes, a lot of people want to download the new version! So let’s see what would actually happen.
- You upload a new version of a large file.
- You send a purge request for that file to the CDN.
- You send an email advertising that there is a new version of the file
- Over the next 10 seconds after you sent the email, 100 different persons (in the same location, for the sake of the example) start downloading the file.
- Assuming it takes 10 seconds for the CDN to retrieve the file from the origin, for 10 seconds following the first request, the file will not be in the CDN’s cache yet.
- Since the CDN does not have the file in cache when those 100 requests are received, the CDN makes 100 requests to the backend, which serves the same large file 100 times.
This is quite impractical. Therefore, to reduce the impact on the origin, modern CDNs will use request collapsing(or: Coalescing). Request collapsing is an optimisation where the CDN will realise, upon receiving one of these 100 requests, that it already is retrieving that file from the backend for an earlier request. It will therefore “park” the request, waiting for the earlier request to complete. Once the earlier request is completed, the file will be served from cache for all “parked” requests. We say that those “parked” requests are “collapsed” into the earlier request.
What happened?
- The first request returned content served by the origin, it was a cache MISS.
- The other 99 requests were not sent to the origin, served data from the CDN cache, populated by the first requests. They are, technically, cache HITs.
Unintuitively enough - while the requests that returned cache HITs did not go to the origin, they were waiting, some for up to 10 seconds, for the first request to complete. According to the RFC 9211, those are even cache MISSes…
Another case of cache-HISS?
Multi-Tiered architectures
In an earlier blog post about the execution model of AWS Lambda@edge in Cloudfront, I briefly touched on the concept of multi-tiered CDN architectures. Indeed most CDN nowadays [Cloudflare’s orpheus, Cloudfront Origin shield, Fastly shielding] enable the configuration of multiple layers of caching, 2, sometimes even 3.
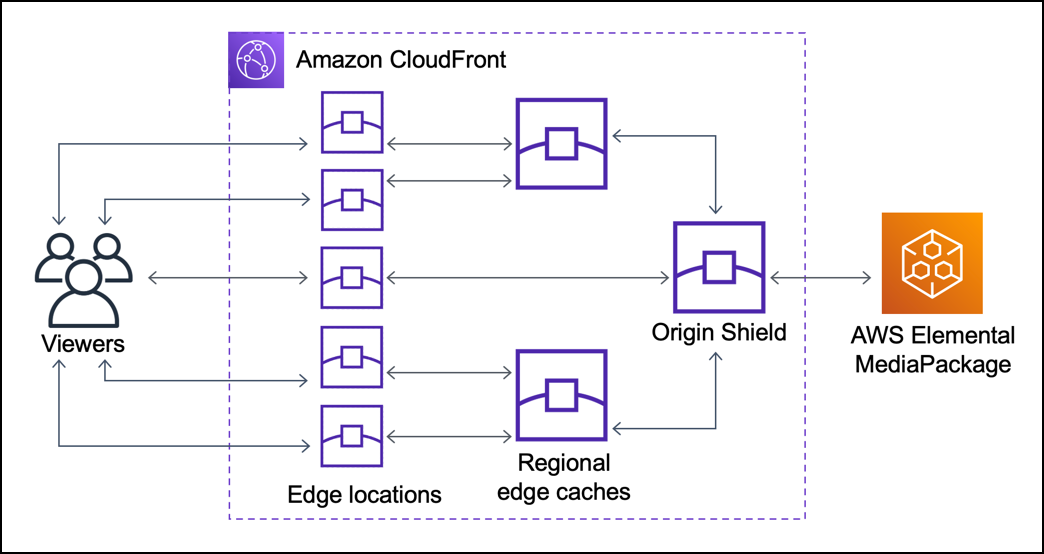
In this example of a three-tier setup with Cloudfront, the “edge location” will be geographically quite close to the user - but the “origin shield” will be geographically much closer to the origin, and potentially quite far from the user. What this architecture implies - is that a request might be a HIT or a MISS in every of the different caching layers.
Let’s take the following use-case: your origin is located in Virginia (US-East), and uses a CDN using a three-tiered architecture such as the one presented above. A user from India requests a 1KB file. Noone in India requested that file before, therefore neither the edge location nor the Regional Edge Cache has the file in cache. The request therefore goes all around the globe to the origin shield cache in US-East. Someone in the US requested that file earlier, therefore the file is in cache in the origin shield, and the request is therefore a cache HIT in the shield.
What happened?
- The request never reached the origin. It is a cache HIT.
- However, the request had to go all around the planet to reach the origin shield, and was barely faster than a non-cached request.
Also a cache-HISS?
Serving stale content
When a file is cached by a CDN and its TTL expires, or if you purge that file from the CDN, the CDN will often keep the file in cache for a little while and mark it as “stale”, instead of directly deleting it. This is because in some cases, you might decide that serving content that is slightly out of date is better than the alternative.
The most common case is when the TTL of a cached file in the CDN expires, and the CDN tries to fetch a new version from your backend server. What if there is an error fetching the new version, because your fileserver is currently overloaded or down? Would it be better to serve a 5xx HTTP error - or a slightly outdated file?
This behaviour is known as stale-on-error and is available with most CDN providers. Depending on your business requirements, this might be a good option to turn on.
Let’s take the following example:
- A user requests a file
- The CDN has a cached version of that file, but since the TTL of that cached object expired, it forwards the request to the backend server
- The backend server is currently overloaded - the connection times out after several seconds.
- The option “stale-on-error” is turned on - therefore the CDN serves the stale object from cache.
What happened?
- The file was served from cache - it is a cache HIT
- The request went to the origin (or tried to). It was very slow to complete since the CDN waited for a timeout to occur before giving up and serving the stale file.
Cache-HISS!
Final thoughts
Looking at a single qualifier for a request, “HIT” or “MISS”, tells us very little about what really happened. In some cases, the request might hit a caching layer half way around the planet, wait for another request to complete, hit a timeout or an error, or even hit the origin and require computation there. By extension, a cache-hit ratio will fail to convey any information about user experience, or how many requests reached the origin.
The Cache-Status HTTP response header introduced by the RFC 9211 is a really interesting attempt at improving the situation and providing a standard way of exposing and tracking CDNs' caching behaviour. It recognises that to get meaningful information about a request, it is important to take into account the cache behaviour at each caching layer. It also provides a clear definition of what cache HITs and a cache MISSes are.
It is however pretty recent and implementation of that RFC is sparse. Most CDNs providers present some aggregated cache-hit ratio. Forget about it, and measure what matters:
- Latency : This is often the most important, since latency is a good measure of user experience. How fast was the file served to the user? This can be measured using instrumentation on the client side, for example using a “RUM” (Real User Monitoring) solution. Most monitoring/observability providers will have a RUM product, which will usually rely on the Resource Timing API. Note that these will account for connection issues on your clients' side - poor WiFi, ISP troubles, might point to issues you can only do very little about. Another approach could be measuring at the CDN edge, for example through logs: tracking the TTFB, or total request time, might be meaningful proxies to user experience.
- Bandwidth reduction at origin: Tracking how much your CDN helps reduce the bandwidth on your origin might be a good indicator of how much egress costs it is helping save. For this, compare the egress bandwidth from your origin, to the egress bandwidth of your CDN.
- Origin load reduction: If requests to the origin require a lot of computation, reducing how many requests hit the origin is very important. Compare the number of requests forwarded to the origin and the total number of requests received by the CDN.